About
What Is RustSEG
RustSEG is corrosion semantic segmentation algorithm developed as part of an honours thesis undertaken at the Australian National University. This method can take most images, then using deep learning determine if the image contains corrosion (rust). From this it generates a heatmap of pixels that have a high likelihood of containing corrosion based on the neural networks thinking. Some post-processing is applied and RustSEG can show the user where in an image rust is present by drawing a segmentation mask on the image. The special part of this method is that the algorithm never received any segmentation training data, just a series of photos it was told contained corrosion and a series that did not contain corrosion.
One of the main reasons for this research is that per-pixel labelled segmentation training data for corrosion basically do not exist. To date the largest per pixel data set stands at 608 images and was created for Fondevik et. al. One of the main reasons these dataset don’t exist is that regular people struggle to correctly identify corrosion and are particularly bad at determining corrosion boundaries. This means that data sets can not be crowd sourced like other segmentation data sets such as MS COCO. This research was an investigation to if segmentation masks could be generated using only classification data which is much easier to source.
What is Semantic Segmentation:
Segmentation of images is the act of generating pixel-wise masking of specific classes of object present in an image. Semantic segmentation is when you also identify what each mask represents. In lay terms it is outlining and identifying objects in image.

What is Semantic Segmentation:
When discussing segmentation, it is important to distinguish between semantic segmentation and instance segmentation. In semantic segmentation we are interested in every instance of a class within an image, but do not try and differentiate between those objects. i.e. we want to find every pedestrian but do not care about the difference between person one and person two. In instance segmentation we are trying to label each ‘instance’ of a class that appears in an image.

How Semantic Segmentation “Normally” Works:
The segmentation of images is no new idea. Researchers have been interested in the segmentation of objects in images for some time. Originally, non-machine learning techniques were used such as K-Means clustering. These methods had no way of identifying what the object they were outlining was, but in some cases were very affective at generating segmentation masks.
More recently researchers have been using neural networks to train model to identify and outline certain objects in images. These models are fed thousands of images that have per-pixel masks already drawn, usually using crowdsourcing or paying people to outline images. Now, when researchers are building new deep learning models for semantic segmentation there are huge publicly available data sets they can use to train and evaluation their models. Some popular data sets are:
MS COCO: >200K labelled images containing 1.5 million labelled objects of 80 different classes.
ImageNet-S: 1.5 million images 40K annotation (Regular ImageNet is for classification and has over 14 million images)
PASCAL VOC: ~20k (with around half for testing)
These huge datasets are ‘fed’ into a deep learning model to learn what certain objects are and how to outline them in an image
To date researchers have been very successful at this task. Researchers have been able to achieve ~90% accuracy in general semantic segmentation of a large number of classes.
Semantic Segmentation of Rust
These huge data sets for rust don’t exist. Rust is complex and difficult to label. To correctly label these data sets you would require experts to label thousands of photos. These experts are expensive, and the task is dull and boring. To date the largest per-pixel labelled dataset for rust is the one described in Fondevik et. al. It contains 608 images with 4031 instances labelled. Due to this lack of labelled datasets my work looks for an effective method to generate segmentation masks without per-pixel data.
Data set for RustSEG
To train the convolutional neural network side of RustSEG a large data set of images corrosion images and non-corrosion images was obtained by scrapping popular image hosting website Flickr. To obtain images of corrosion keyword searches such as : “corrosion”, “rust”, “rusty car”, “rusty bolt” were used. For non-corrosion images the keyword searches were chosen using two methods. First are categories known to trick both human and CNNs, these included terms like: “brick”, “wooden boats”, “graffiti” and “brioche”. The other type of non-corrosion images were supposed to represent everyday life objects and scenes, the search terms for this include: “people”, “outside”, “homes” and “animals”. The data sets were lightly checked mostly to remove animated or rendered images, NSFW images and the band called “Corrosion”. Currently the data set the classifier is trained on is 7000 images of corrosion and 9000 images of not corrosion.

The Model Architecture
The classifier network is based on the method used for corrosiondetector.com which is in turn based on the encoder side of U-Net. It is a 10-layer convolutional neural network. This means the model learns a series of filters that are convoluted over the image to identify features that can help the model determine if corrosion is present. After two blocks of convolution layer the output is max pooled. This has the effect of shrinking the height and width by half and increases the depth of the layer. By using this approach, the model is going from small detail features to larger special filters as the convolution layer shrinks.
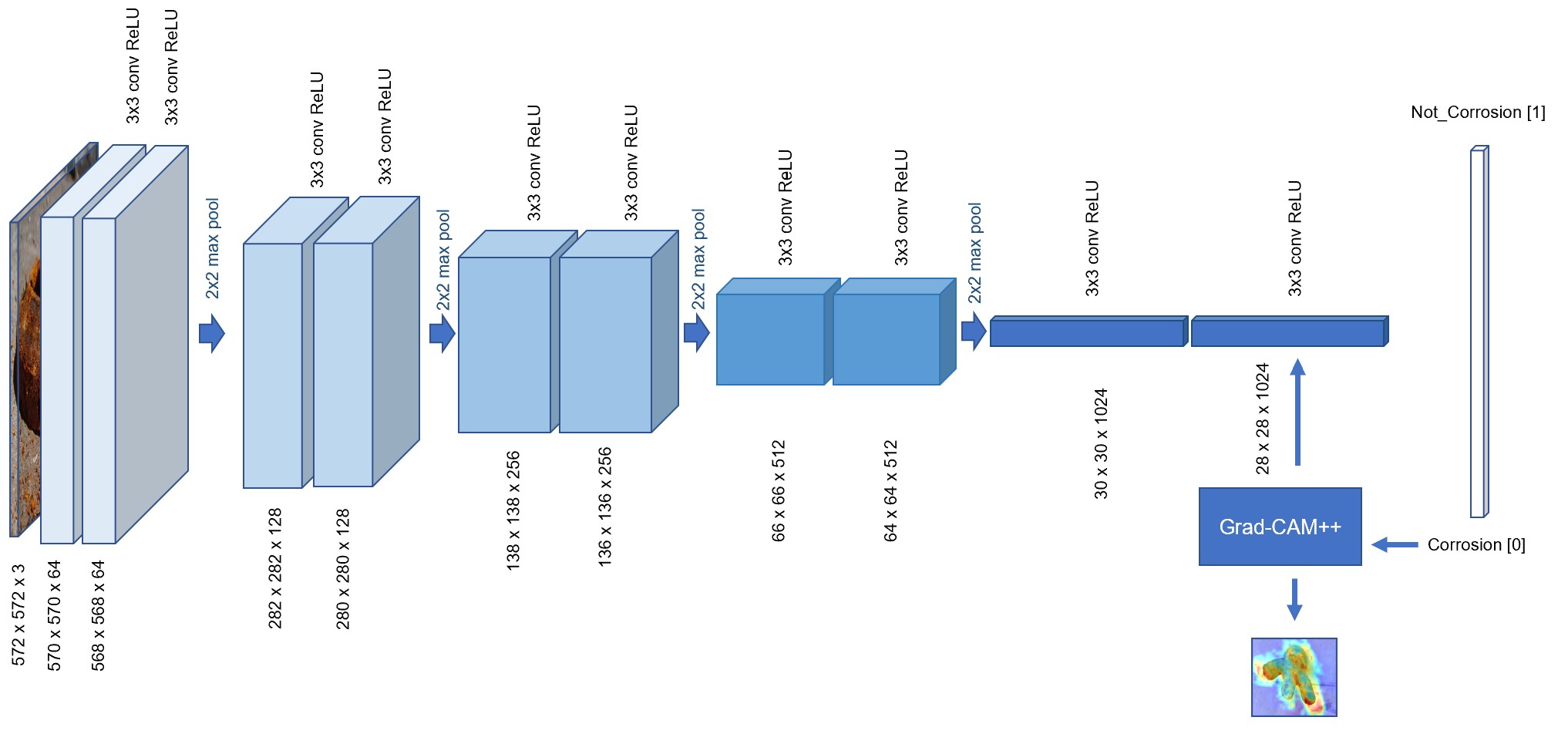
Workflow
The workflow for this method can be broken up into 3 main stages. Classify, Localise and Refine. The Classify method uses the above model to parse an image and determine from learned features if corrosion is present. If corrosion is detected the image is passed off to the Grad-CAM++ module. This model calculates the gradients of the class that won with activation maps of the final convolutional layer. This allows the method to determine which pixels that had the most influence on classifier model making its prediction. Unfortunately, this technique is limited by the size of the final convolutional layer, this mean the heatmap of useful pixels is limited to 28x28 grid. To refine this into a useful segmentation mask this heatmap and the original image is passed to the final stage; Refine. This stage takes the heatmap, applies a dynamic threshold filter to convert the map into a rough mask. The mask is then refined by a Conditional Random Field (CRF). This CRF grows or shrinks the mask based on colour and texture of surrounding pixels. Finally, the mask is super imposed on the image for the user.
